 Hi, I am Gaurav Pendharkar!
Hi, I am Gaurav Pendharkar!
a data scientist driven by a passion for building interpretable, reliable, and deployable ML systems using domain-specific data.
About Me
My name is Gaurav Pendharkar. I am a data scientist with 1.5 years of experience developing machine learning pipelines for practical applications across various domains, including law, healthcare, earth sciences, and aviation. I have expertise in managing diverse data sources, including structured data (tables), semi-structured data (JSON, XML), and unstructured data (text, images, and PDFs). My focus is on building explainable, reliable machine learning systems through transparent modeling choices and rigorous evaluation in real-world environments.
Experience

- Engineered a tree-based ML system for estimating soil pH and organic matter on 242 samples, reducing lab-tested features by 87%, leading to a 25% reduction in lab equipment costs using Python and scikit-learn.
- Built a rocky-terrain classifier based on topographic and vegetation features to control downstream models, boosting macro-avg recall by 30% (0.56 to 0.72), and halving unreliable predictions in low-soil-sample regions.
- Orchestrated a GenAI workflow for soil pH regression, decreasing MAPE from 9% to 5%, enabling 25x faster experimentation with manual-like error margins through chain-of-thought prompting on Gemini 2.5 Flash.

- Worked with 2 researchers to enhance a multilingual rich-text editor by expanding support from one to three low-resource Indian languages, increasing linguistic inclusivity across India by 36% using AI4Bharat models.
- Replaced speech recognition with a word-by-word transliteration via IndicXlit and FastAPI, improving accuracy and reducing response time from ~30s to ~17s (43%).
- Migrated from a limited Google Translate API integration to IndicTrans with FastAPI, improving translation quality and removing usage limits.

- Automated acquisition of criminal case PDFs from the Manupatra legal database with Python and Selenium, expanding the dataset by 205% (455 to 1388), saving 15+ hours of manual collection.
- Fine-tuned the LAW entity from the named entity recognizer on 150 training examples leveraging SpaCy, boosting the F1-score from 0.40 to 0.83, resulting in 8% improvement in downstream case outcome prediction.
- Built a NLP pipeline combining fine-tuned NER and regex to convert unstructured documents into a structured form, reducing manual processing time by 99.8% (3 months to 12 hours), scaling throughput to 2 docs/min.
Recent Projects
View all projects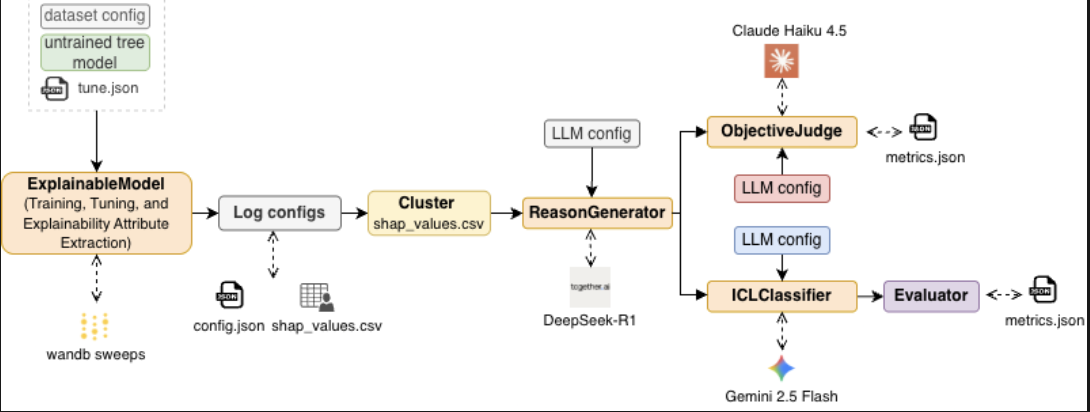
Explainability Driven Chain-of-Thought Prompting
Automated reasoning for CoT prompting using explainability attributes from tree-based models for binary classification on tabular datasets.
 View on GitHub
View on GitHub
Daily Sales Forecasting
Forecasting daily total sales of different gifting items using holiday data, promotional sales data , and other time-series features.
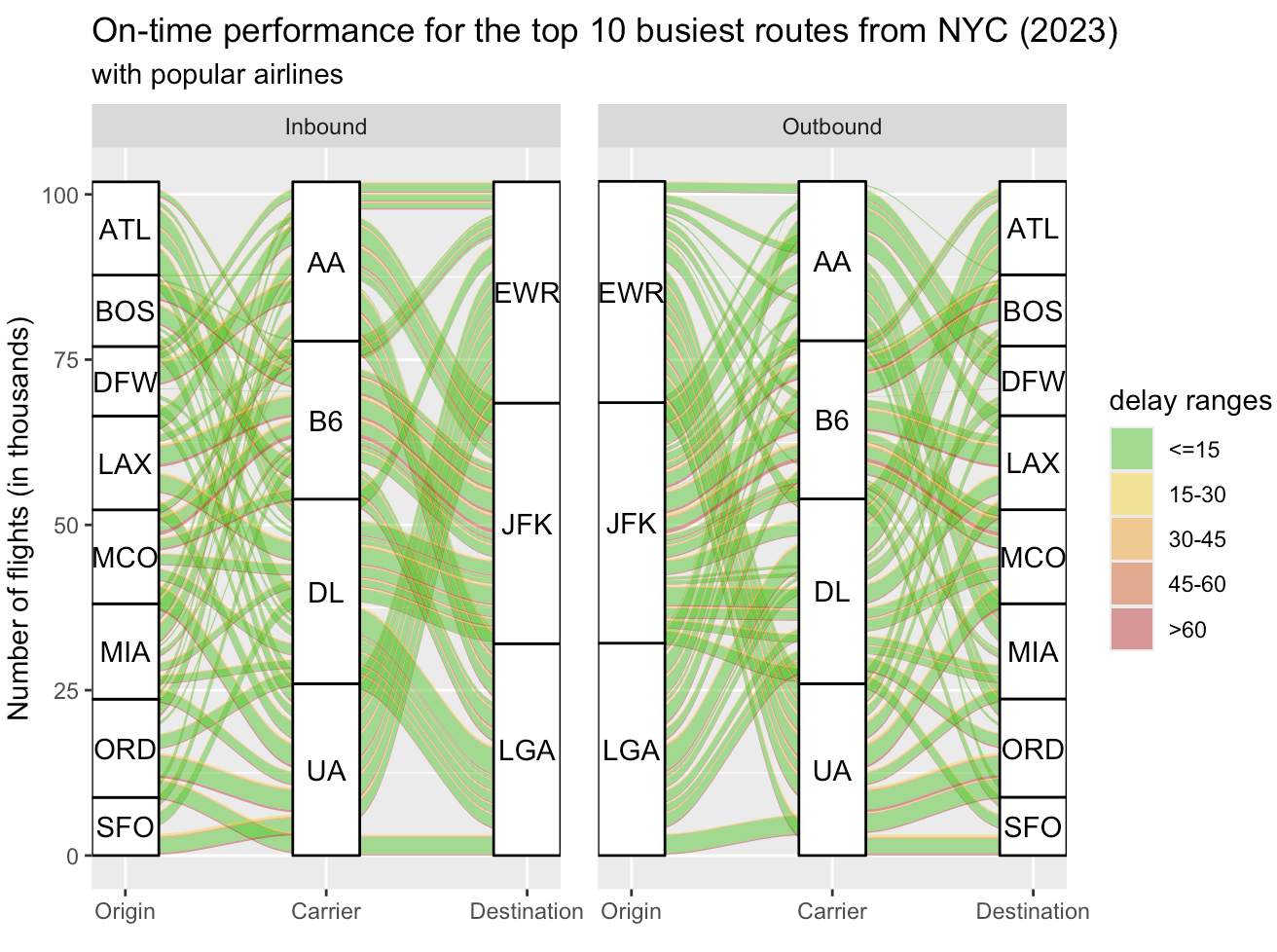
On-time Performance Analysis of NYC domestic flights
On-time performance analysis of domestic flights from NYC airports for the year 2023.
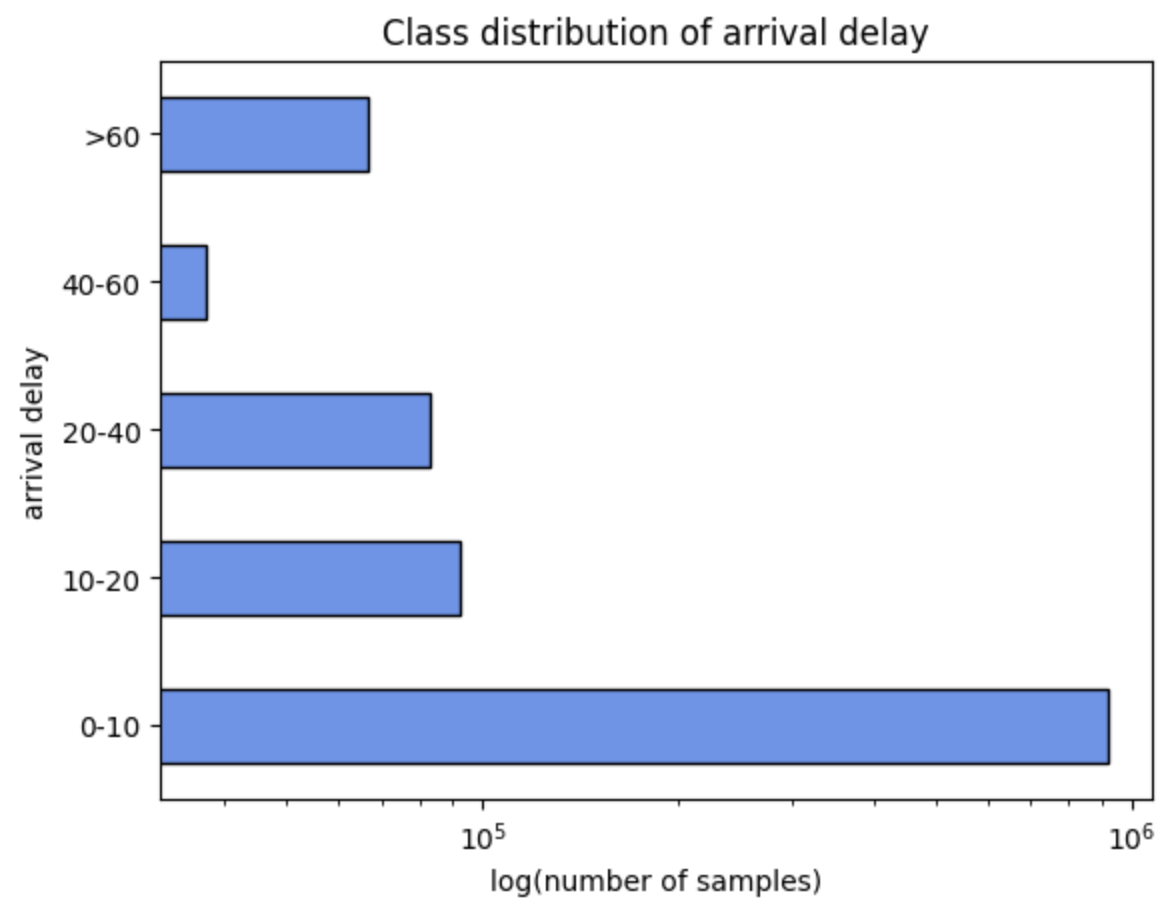
Arrival Delay Prediction for US domestic flights
Multiclass classification of arrival delays for NYC domestic flights using tree-based models.

Illumination Invariant Tiger Detection
Automating detecting tigers in the wild by handling illumination issues with the help of EnlightenGAN.

Imbalanced Malware Byteplot Image Classification
Assessing the impact of class imbalance on model performance and convergence for malware byteplot image classification.
My Skills
 Python
Python
 Python
Python
 SQL
SQL
 SQL
SQL
 R
R
 R
R
 TypeScript
TypeScript
 TypeScript
TypeScript
 Pandas
Pandas
 Pandas
Pandas
 OpenCV
OpenCV
 OpenCV
OpenCV
 scikit-learn
scikit-learn
 scikit-learn
scikit-learn
 PyTorch
PyTorch
 PyTorch
PyTorch
 TensorFlow
TensorFlow
 TensorFlow
TensorFlow
 Weights & Biases
Weights & Biases
 Weights & Biases
Weights & Biases
 HuggingFace
HuggingFace
 HuggingFace
HuggingFace
 spaCy
spaCy
 spaCy
spaCy
 Google Cloud Platform
Google Cloud Platform
 Google Cloud Platform
Google Cloud Platform
 FastAPI
FastAPI
 FastAPI
FastAPI
 Cursor
Cursor
 Cursor
Cursor
 GitHub Copilot
GitHub Copilot
 GitHub Copilot
GitHub Copilot
 Grammarly
Grammarly
 Grammarly
Grammarly
 GitHub
GitHub
 LaTeX
LaTeX
 LaTeX
LaTeX
 Markdown
Markdown
 Markdown
Markdown
 Selenium
Selenium
 Selenium
Selenium
 Jupyter
Jupyter
 Jupyter
Jupyter
Education
